ERROAR!#4 The Oral Logic
dimension variable
single-channel HD video(3’25”, sound), interactive web-based application, laser-engraved mirror, 3D prints, generative poetry on paper scroll, algorithmic composition (in collaboration with Jason Doell)
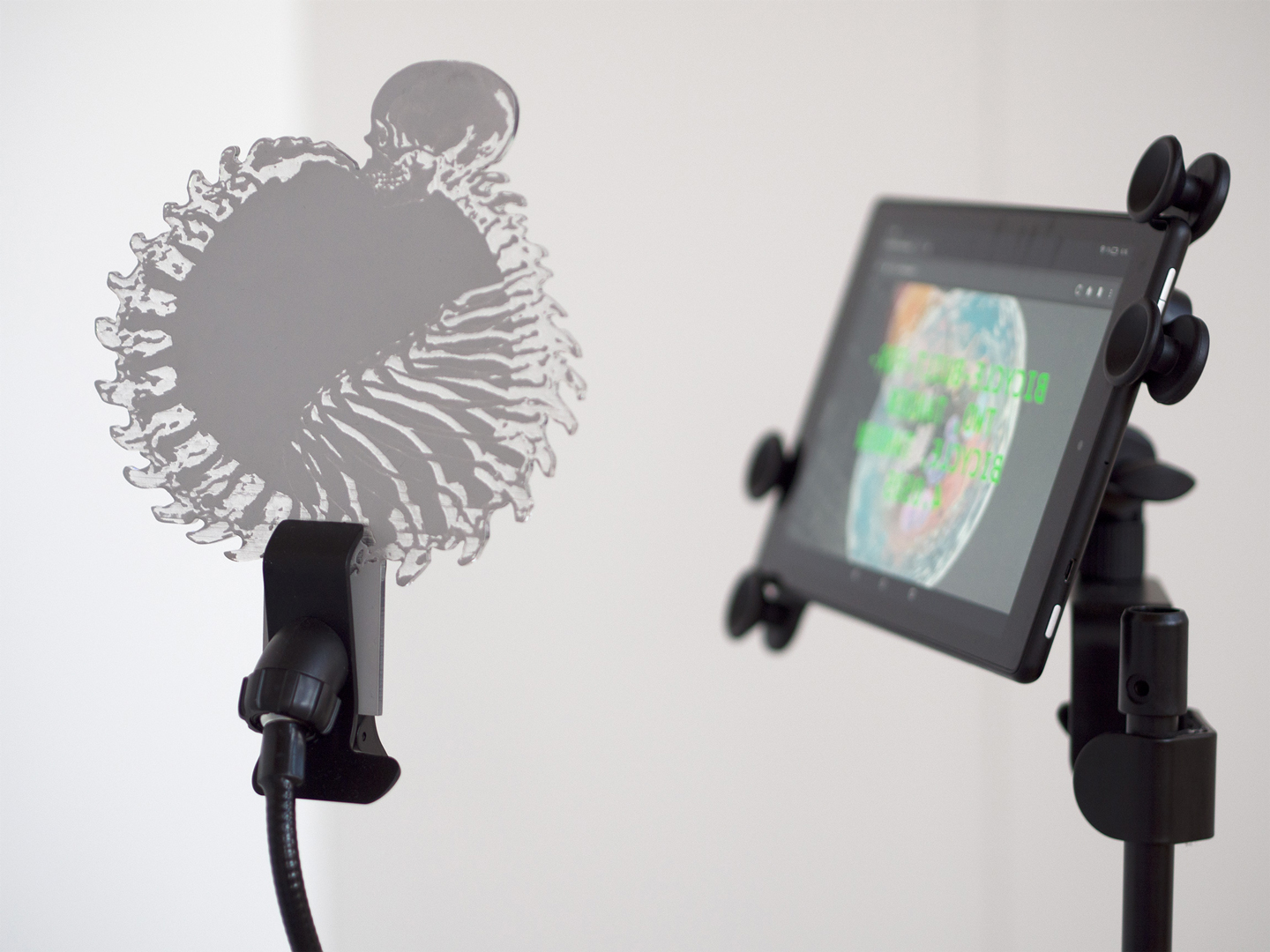







ERROAR!#4 contemplates on the phenomenon of “cannibalism” as a metaphor for cultural and technological assimilation, especially in the process of human-artificial-intelligence coupling. Entirely composed of stock videos, the single-channel video essay is derived from an online anecdote about the first case of “virtual cannibalism” conducted by AI agents during DARPA’s early experiments. The piece of generative poetry titled “Past Said Lore” on the paper scroll is co-authored with a recurrent neural network to write in the style of John Milton’s Paradise Lost. Through a webcam and a mirror, the networked software “misrecognizes” human faces as “objects”, due to incorrect and incomplete training and learning. Being objectified by an object in error creates an infinite feedback loop between the mirror and the camera, performing a metaphorical autophagy, just like the closed loop of human skeleton eating tailbone.
The Erroar! Series speaks to the errant and noise that emerge from experiments of intelligence agents for understanding human’s cognitive functions through artificial neural networks, and how these technological errors open up new creative potentials that in return reconfigure our perceptions, affect and imaginations. Most visual-textual-sonic materials involved are generated from the process in which artist use open data in various formats to train prevalent machine learning algorithms.